Understanding the Cost Structure
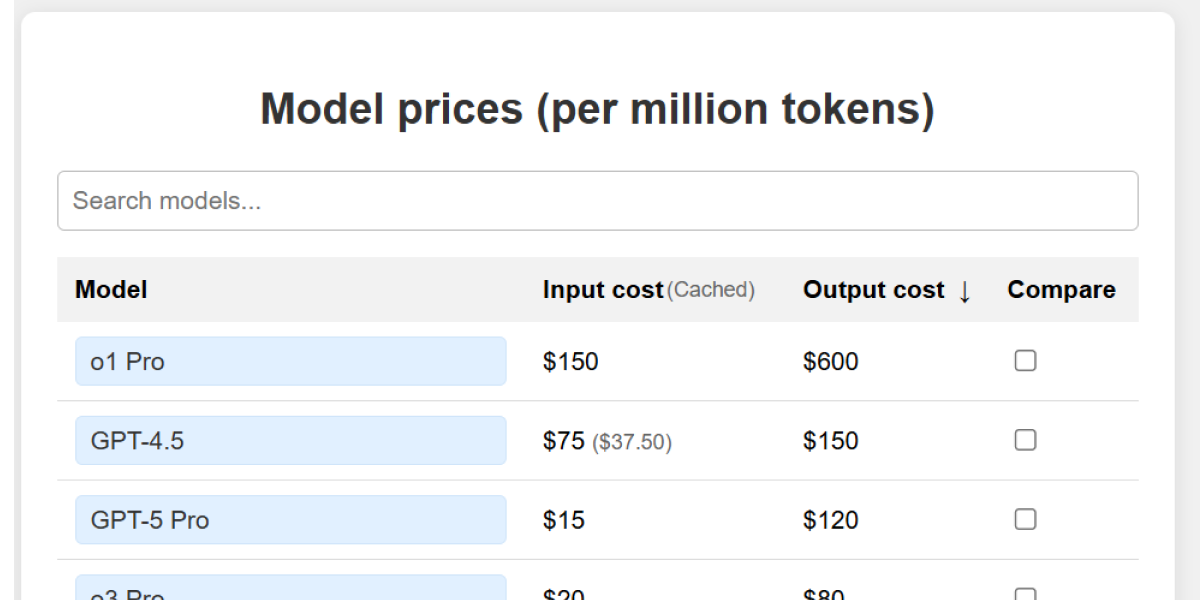
LLM API pricing is token-based. Costs scale with both input and output tokens. As of 2025, pricing ranges from $0.15 per million tokens for efficient models like GPT-4o mini to $15+ per million tokens for reasoning models. A company running 100 daily active chatbots, each consuming 50,000 tokens, would spend roughly $4,500 monthly at GPT-4 Turbo rates.
Total costs include more than token pricing. Companies must account for request volume, prompt design, context windows, and latency needs. An effective optimization strategy addresses all of these.
Cost Optimization Strategies
1. Model Selection and Routing
Smart model selection can reduce costs by over 300x. Model prices vary dramatically across capability tiers. Research on LLMProxy showed that intelligent model routing combined with context management reduced costs by over 30% in production.
The best approach: route simple queries to cheap models and save expensive models for complex tasks. Use cascading fallback logic. A cheap model tries each query first and passes to a more capable model only when needed. This cuts average per-query costs.
How to implement: Start by categorizing your queries by complexity. Use services like OpenRouter or Portkey that support multi-model routing with fallback logic. Set up A/B testing to compare cheap model outputs against expensive ones for different query types.
2. Context Management
Context management affects both latency and cost. Conversational apps accumulate tokens linearly. A two-minute voice call can generate 300+ words of dialogue history.
Ways to optimize context:
- Use rolling context windows that keep only recent conversation turns
- Compress old context with summarization before adding to prompts
- Remove redundant system instructions from multi-turn conversations
- Use prompt caching for stable prompt prefixes
Major providers now price cached input tokens at 50% of standard rates.
How to implement: Configure your conversation history to keep only the last 5-10 turns. Use a cheaper model to summarize earlier context when conversations exceed this limit. Enable prompt caching in your API calls.
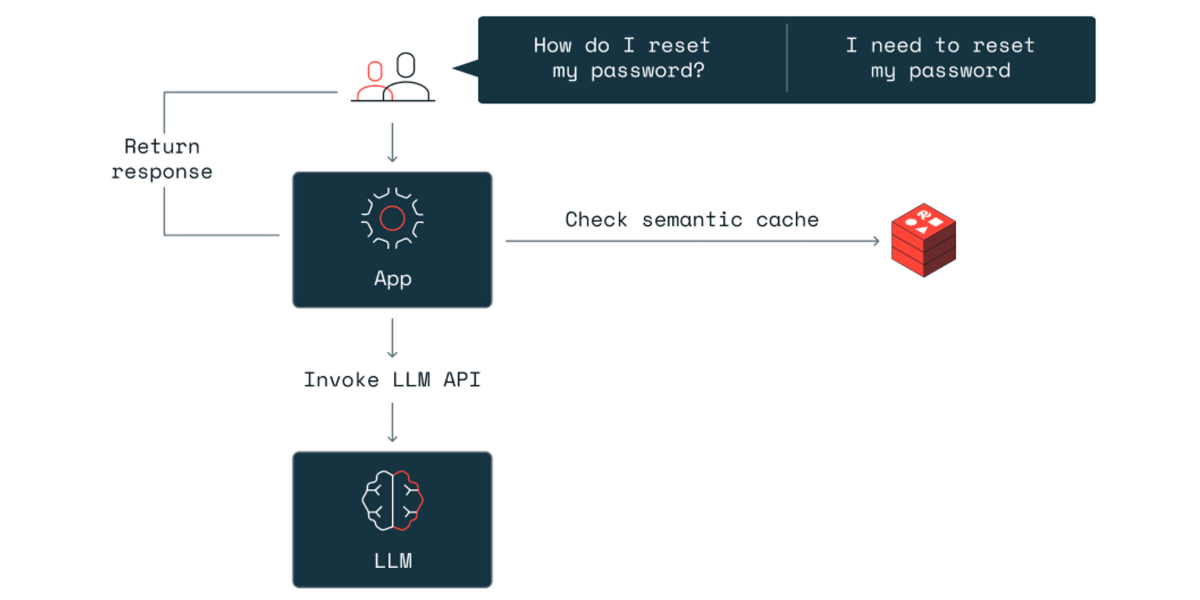
3. Semantic Caching
Semantic caching is a high-impact technique backed by recent research. Unlike exact-match caching, semantic caching finds queries with similar intent. This lets you reuse responses even when phrasing differs.
Multiple peer-reviewed studies confirm its effectiveness. A 2024 study published on arXiv showed that semantic caching reduced API calls by up to 68.8% across various query categories. Research on MeanCache achieved 17% higher F-score and 20% increase in precision while reducing storage requirements by 83%.
Analysis of real-world query patterns shows that roughly 31% of user queries match semantically with at least one previous query by the same user.
How to implement: Use single-line integration solutions like Kento that work with your existing API calls. For custom implementations, use Redis for in-memory storage with semantic embedding similarity matching.
4. Batch Processing
For work that doesn't need instant results, batch API endpoints offer 50% discounts on models like GPT-4o and Claude. Companies processing large volumes of classification tasks, content analysis, or data enrichment can save money by deferring these operations to batch queues.
Batch processing works well for:
- Overnight data enrichment pipelines
- Bulk content moderation
- Large-scale document classification
- Historical data analysis
How to implement: Use the Batch API endpoints from OpenAI (/v1/batches) or Anthropic's Message Batches API. Structure your requests as JSONL files with one request per line. Set up nightly cron jobs for recurring batch work.
5. Prompt Engineering and Optimization
Well-structured prompts that minimize unnecessary tokens while maximizing response quality help across all optimization methods. Effective prompt optimization includes:
- Remove verbose instructions and replace them with short directives
- Cut redundant examples when few-shot learning isn't needed
- Structure outputs to request only essential information
- Use system messages efficiently to set persistent context
Industry practitioners report that prompt optimization alone can reduce token consumption by 15-30% without hurting output quality.
How to implement: Use prompt testing tools like Anthropic's Prompt Engineering Console or OpenAI's Playground to compare different prompt versions. Measure token count for each variation. Use structured output formats (JSON, XML) to eliminate parsing overhead.
6. Fine-Tuning for Specialized Use Cases
Companies with high-volume, specialized use cases and enough labeled data can cut costs and improve quality through domain-specific fine-tuning. Fine-tuned models often perform better on narrow tasks while needing shorter prompts.
The economic threshold for fine-tuning varies by use case, but companies processing millions of similar queries monthly typically find it worthwhile.
How to implement: Start by collecting at least 50-100 high-quality examples of your specific use case. Use OpenAI's fine-tuning API or open-source models through platforms like Together.ai or Replicate. Calculate break-even point by comparing fine-tuning costs against base model costs.
Measuring and Monitoring Costs
Effective cost optimization needs continuous monitoring. Key metrics to track:
- Cost per business operation (e.g., cost per customer support ticket resolved)
- Cache hit rate by query category
- Average tokens per request over time
- Model routing accuracy and fallback frequency
- Cost attribution by feature, user segment, or customer
Strategic Recommendations
Companies seeking to optimize LLM API costs should prioritize work by implementation effort and expected return:
- Set up cost monitoring before costs become a problem
- Review current workloads to find quick wins
- Use caching strategies appropriate to your use cases
- Test model routing opportunities
- Use batch processing for asynchronous work
- Build prompt engineering discipline
Conclusion
Production data shows that most companies achieve 30-50% cost reductions through complete optimization. Some use cases reach 90% savings. Results depend on how many techniques companies apply together and how disciplined they are about continuous optimization.
A telecommunications company cut monthly LLM costs from $48,000 to $32,000 by moving chat triage work to self-hosted models. For companies below this threshold, API-based approaches with smart model routing, aggressive caching, context management, and batch processing typically deliver better total cost of ownership.
The question is no longer whether to optimize LLM costs, but how quickly companies can apply proven techniques before uncontrolled costs limit their AI goals.
References
- Regmi, S., & Bhatt, S. (2024). GPT Semantic Cache: Reducing LLM Costs and Latency via Semantic Embedding Caching. arXiv preprint arXiv:2411.05276.
- Gill, W., et al. (2024). MeanCache: User-Centric Semantic Caching for LLM Web Services. arXiv preprint arXiv:2403.02694.
- Wang, C., et al. (2024). Category-Aware Semantic Caching for Heterogeneous LLM Workloads. arXiv preprint arXiv:2510.26835.
- Menlo Ventures. (2025). 2025 Mid-Year LLM Market Update: Foundation Model Landscape + Economics.
- Shah, A. (2025). Navigating the LLM Cost Maze: A Q2 2025 Pricing and Limits Analysis. Medium.
- LLMProxy research team. (2024). LLMProxy: Reducing Cost to Access Large Language Models. arXiv preprint arXiv:2410.11857.
- Wang, J., et al. (2024). SCALM: Towards Semantic Caching for Automated Chat Services with Large Language Models. arXiv preprint arXiv:2406.00025.